





.png)
Yes, I’m still on vacation. But I couldn’t resist a quick response to this comment (and the subsequent debate):
BBC: Do you agree that from 1995 to the present there has been no statistically-significant global warming
Phil Jones: Yes, but only just.
Here is the global temperature data from 1995 to 2010, for NASA GISS and Hadley CRU. The plot comes from the Wood for Trees website. A linear trend is fitted to each series.
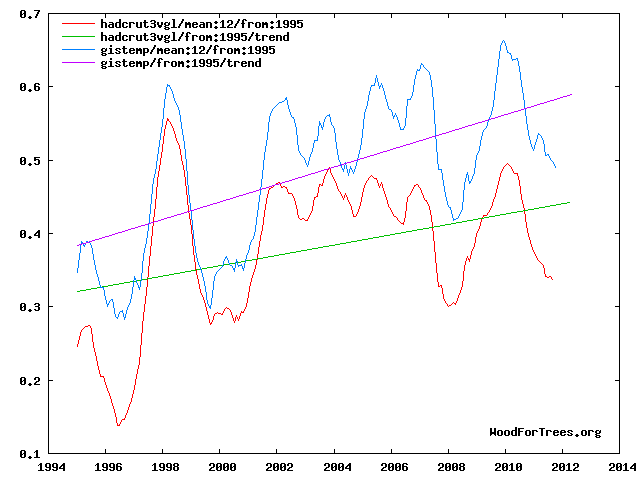
Both trends are clearly upwards.
Phil Jones was referring to the CRU data, so let’s start with that. If you fit a linear least-squares regression (or a generalised linear model with a gaussian distribution and identity link function, using maximum likelihood), you get the follow results (from Program R):
glm(formula = as.formula(mod.vec[2]), family =
gaussian(link = "identity"),
data = dat.2009)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.175952 -0.040652 0.001190 0.051519 0.192276
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -21.412933 11.079377 -1.933 0.0754 .
Year 0.010886 0.005534 1.967 0.0709 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for gaussian family taken to be 0.008575483)
Null deviance: 0.14466 on 14 degrees of freedom
Residual deviance: 0.11148 on 13 degrees of freedom
AIC: -24.961Two particularly relevant things to note here. First, the Year estimate is 0.010886. This means that the regression slope is +0.011 degrees C per year (or 0.11 C/decade or 1.1 C/century). The second is that the “Pr” or p-value is 0.0709, which, according to the codes, is “not significant” at Fisher’s alpha = 0.05.
What does this mean? Well, in essence it says that if there was NO trend in the data (and it met the other assumptions of this test), you would expect to observe a slope at least that large in 7.1% or replicated samples. That is, if you could replay the temperature series on Earth, or replicate Earths, say 1,000 times, you would, by chance, see that trend or larger in 71 of them. According to classical ‘frequentist’ statistical convention (which is rather silly, IMHO), that’s not significant. However, if you only observed this is 50 of 1,000 replicate Earths, that WOULD be significant.
Crazy stuff, eh? Yeah, many people agree.
Alternatively, and more sensibly, we can fit two models: a ‘null’ with no slope, and a TREND model with a slope, and then compare how well they fit the data (after bias corrections). A useful way to do this comparison is via the Akaike Information Criterion – in particular, the AICc evidence ratio (ER). The ER is the model probability of slope model divided by that of the intercept-only model, and is, in concept, akin to Bayesian odds ratios. The ER is preferable to a classic null-hypothesis significance test because the likelihood of the alternative model is explicitly evaluated (not just the null). Read more about it in this free chapter that Corey Bradshaw and I wrote.
Here is what we get:
k -LogL AICc dAICc wAIC pcdev
CRU ~ Year 3 15.48054 -22.77926 0.0000000 0.5897932 22.93616
CRU ~ 1 2 13.52652 -22.05304 0.7262213 0.4102068 0.00000The key thing to look at here is the wAIC values. The ER in this case is 0.5897932/0.4102068 = 1.44. So, under this test, the model that says there IS a trend in the data is 1.44 times better supported by the data than the model that says there isn’t. The best supported model is the TREND model, but really, it’s too hard with this data to separate the alternative hypotheses.
With more data comes more statistical power, however. Say we add the results of 2010 to the mix (well, the average anomaly so far). Then, for the null hypothesis test, we get:
glm(formula = as.formula(mod.vec[2]), family =
gaussian(link = "identity"),
data = dat)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.174040 -0.041956 0.008072 0.044350 0.193146
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -22.456037 9.709805 -2.313 0.0365 *
Year 0.011407 0.004849 2.353 0.0338 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for gaussian family taken to be 0.007993787)
Null deviance: 0.15616 on 15 degrees of freedom
Residual deviance: 0.11191 on 14 degrees of freedom
AIC: -27.996For the ER test, we get:
k -LogL AICc dAICc wAIC pcdev
CRU ~ Year 3 16.99796 -25.99592 0.000000 0.7552163 28.33275
CRU ~ 1 2 14.33287 -23.74266 2.253259 0.2447837 0.00000The ER = 3.1.
So, the “significance test” suddenly (almost magically….) goes from being non-significant to significant at p = 0.05 (because Pr is now 0.0338), or 38 times out of 1,000 by chance.
Whereas although the ER test is strengthened, the previous, result that the TREND is the best model (of these two alternatives), doesn’t change. This test is a little more robust, and certainly less arbitrary because no matter what the data, we are always evaluating the strength of our evidence rather than whether some pre-defined threshold is crossed.
You can do the same exercise with GISTEMP, but it’s less ‘interesting’, because GISTEMP shows a stronger trend, due largely to its inclusion of Arctic areas.
For GISTEMP, the 1995-2009 data yield a slope of 0.0163 C/year, a p-value = 0.0082, and an ER = 13.4 (that is, the TREND model is >10 times better supported by this data). The 1995-2010 (December-November averages) for GISTEMP gives a slope of 0.0174 C/year, a p-value = 0.0021, and an ER = 57.8 (TREND now >50 times better supported!).
You can see that for relatively short time series like this, adding extra years can make a reasonable difference, so longer series are preferable in noisy systems like this.
Okay, does that answer the top quote? I think so, but I’m happy to answer questions on details. Otherwise, it’s back to my holidays (but I’ve got a guest post from DV82XL that I’ll put up on 8 Jan, to re-invigorate our debate out carbon prices)…
Filed under: Clim Ch Q&A, Sceptics






Following.
This goes back to the question what is “climate”. Traditionally, at least way back when I was an undergraduate, climate was said to be a statistic produced over at least 30 years. I appreciate that such definition might be arbitrary, but a line has to be drawn somewhere. Otherwise, we’ll have people cherry-picking a 10-year or a 4-year or an x-year period out of a long-term time series if happens to indicate a trend that fits with their agenda. That is in fact already happening, and one of the reasons for that, imho, the line drawn between climate and weather is not sufficiently respected. (I am not saying that there’s anything wrong with the above post, but I’d just like to say to the BBC that I disagree with their question.:))
Barry,
Are you saying that Phil Jones doesn’t understand his own figures?
Or he doesn’t know what he is talking about?
I’m saying his answer was predicated on the basis of a weak statistical test and measured against an arbitrary yes/no threshold that is inappropriate for answering such questions. I also agree with Dejan that it was the wrong question.
@SD: Your case is weak and unconvincing. To have put it forward in the first place you need to have understood the case for statistical warming and distorted its import. This is not the behaviour of someone seeking to reveal the truth.
Yes, he shouldn’t have been so direct but he did say it and when added to the last 13 decades with an average warming of 0.06c per decade, some of which could be attributable to recovery from the LIA and the last 10,000 years where each successive warm period has been cooler than the one before it with the current one being coolest of all, I confess to remaining somewhat sceptical of AGW but 6, going on 9 billion will always make a difference and that is the real problem.
I apologise if I interrupted your break.
Barry – I cannot resist a tiny bit of teasing.
Is this really the kind of thinking and writing that you do while on VACATION? You must really be a blast at a cocktail party if you think that doing “linear least-squares regression” test of a “null hypothesis” is a relaxing endeavor.
Anyway – thanks for taking the time to put this post up. I guess it is a good thing for me that I did not sleep the ENTIRE time I was in statistics class.
I regard La Nina years which are cool but exceptionally rainy as abnormal. Perhaps the hypothesis to be tested is that there are fewer years which are both cool and dry. That is to say we are undergoing a period of lack of simultaneous coolness and dryness. We can get one but not both. Call this metric (however formulated) as the cool-dry index.
I think it’s time for AGW sceptics to step up to the plate with their own predictions. You’d think for example 6 or 7 of the years 2011 to 2021 will have temperatures within a standard deviation of the long run value. Are they prepared to put that prediction on record?
Barry, two questions if I may. 1) What is the function and significance of the dispersion parameter and how is it determined? 2) What is the accuracy of the raw input data from NASA GISS and HADCRUT, i.e. to how many decimal places and what variance?
@J McE:
Barry is on holidays, and probably wants to spend time in traditional family activities with his kids… like teaching them tensor calculus or something.
Rod, I actually do enjoy tinkering with this stuff. So SD, nothing to apologize for soliciting this short post!
John Mc, the dispersion parameter is often used to calculate a scaled deviance for the standard errors. It’s calculated as the residual deviance divided by the degrees of freedom (try it). But it’s not relevant to any of the statistics I mention or use here (-LogLik, k, t statistic etc.). One could get the same result without scaling the deviance, or indeed by fitting via ordinary least squares rather than a Hessian matrix, and then using the residual sum of squares to calculate the maximum likelihood estimate that way.
The raw data are available on the links I supplied, the global yearly mean anomalies are reported in each case to 3 decimal places, but the precision for any particular estimate is around 0.05C. I assume you mean this, rather than the year-to-year variance of the data.
As always in these arguments, the choice of start year is all important. Things look a little different if one chooses 1998 as the start year, as so many deniers like to do.
Taking a longer view, the IPCC chose 1850 as the start year in their AR4 “Executive Summary”. Clearly a good choice if one’s aim is to exaggerate the warming trend.
Following
[…] No (statistical) warming since 1995? Wrong
[…]
That’s only 1/2 right GC. If you anchor the end date at 2009, then no matter what year you choose as the start date, pre-1995, you end up with the same conclusion – an upwards trend. No amount of cherry picking can rescue the null model, statistically speaking, as the number of data points increases.
It’s only for post 1995 that this selection chicanery ‘works’, a point I’m sure you acknowledge, and one relevant to the main thrust of this post.
My preferred analogy is that weather is like the waves at the beach whilst climate is more like the tide. We can’t really predict waves very far in advance because they are chaotic but we can predict tides quite accurately over long periods of time.
I’m not suggesting that climate prediction is anywhere near as good as tide prediction, merely that being bad at weather prediction doesn’t imply that we couldn’t in principle get good at climate prediction.
In terms of cherry picking weather events to make an argument about climate it seems to me that both sides of the debate are quite guilty. We had the likes of Tim Flannery using the Australian drought as evidence that the world is warming. Now some are using the record cold in Europe and the USA to poo poo the warming theory (or at least to poo poo those that said snow would soon become a distant memory). I suspect that this is a product of the news cycle and the need to make the theory tangible for ordinary folk. In much the same way as people use weather events to affirm and also to deny the existence of God.
Is 1.1 degrees per century a big deal? If my kids reproduce at the same age that I did then by the time the temperature is up 1.1 degrees my grandkids will have one foot in the grave. An interesting intellectual problem but hardly something to get too excited about.
the 1.1 degree/century number may not be a big deal but it’s also irrelevant since it does not predict the changes in the future century, which depend upon growing ghg concentrations and climate sensitivity (which incorporates feedbacks).
Good anology re climate versus weather,TergeP.
While the math is well beyond me I do respect the abilities of the people concerned.
However,it reminds me of the argument about how many angels can fit on the head of a pin.We know that the angels exist only in the minds of the beholders but the pin is real.
The pin (climate change) is being driven into a sensitive part of our anatomy.How much pain has to be inflicted before the prospect of angels recedes and we start doing something effective about the pin?
Terje it’s not only the slow temperature trend but the prevalence of extremes. Evidenced by slightly crazy talk like ‘for the second time this year we had a once in a century flood’ or ‘farmers should be able to claim drought assistance for flooding’. The public may have deep misgivings as to what lies ahead, just so long as it doesn’t increase their power bill.
John – the story of AGW, seen from the perspective of people that rely on the media, seems to have a capacity for constant morphing. One minute we are being told it may never rain again in Australia because of AGW, then we are being told it is raining so much because of AGW. in Europe they were being told that it might hardly ever snow again because of AGW, now the extreme amounts of snow are being attributed to AGW. People can be forgiven for feeling like it’s all astrology and tea leaves. And all because people are keen to make alarmist, over confident pronouncements on the basis of AGW theory. The advocates have routinely over played their hand when modesty would have been better placed.
My objections to climate science exist but are quite limited. My objection to the politics of climate change advocacy, and the associated economic analysis are many. There are too many people screaming “the sky is falling”. And too many advocating stupid solutions. Given human nature I suppose it’s all rather predictable but still very disappointing.
Finrod,
“@SD: Your case is weak and unconvincing”
I wasn’t aware I’d made a case for anything. Just quoted a scientist who advocates AGW.
I find it is always best if you can form your own opinions based on simple, unarguable evidence and one bit of this is a sea level benchmark I have used for the last 48 years which I built then to the existing king tide levels of that era.
During last year’s El Nino,the king tides were around 40 cms [16 inches] lower than the king tides of 1963. With the current La Nina, present king tides are only 8 cms [3 inches] lower than 1963 indicating how the La Nina increases SLs on the east coast of Aust.
I realise that this is only a rough guide but it is better than any local tide gauges which do not go back further than about 10 years and if king tides are not any higher than they were 50 years ago then there is not much happening with sea level rise.
This benchmark BTW is about 60 metres long, level reinforced concrete on alluvial sand and it is still level after 48 years so IT hasn’t moved .
drongo,I know Moreton Bay is a pleasant view,at least superficially,But you have fallen into the trap of extrapolating local observation to the general,just like those who confuse weather with climate.
Sea levels differ across the globe for various reasons.What the science is telling us is that the overall level has been and is rising and at an increasing rate.At the moment this is mainly due to thermal expansion due to higher temperatures.
When melting ice sheets start contributing in a big way then I am inclined to think your benchmark will be underwater most of the time.I hope you have a Plan B if you of an age where you may still be around for this long term flood.
Would it be fair to say AGW is driving the world towards more active weather, rather than in the direction of overall warmer weather?
I’d describe it as more volatile weather within a climate that was on whole, warmer. Bear in mind also that the mass media pays virtually zero attention to ocean climate, temperature or weather.
The Earth is definitely getting warmer (gaining energy). That wss the point of this post.
This can result in climate disruption, which can manifest in extreme events (heat waves, torrential downpours, deep drought, etc.) or in shifts in weather patterns (seasonal progression, southward drift of the subtropical ridge, Arctic heat pushing frigid air over Europe whilst Greenland heats, etc.).
A 1.1 C trend per century would be significant, and the NASA data suggest that the actual trend is already closer to 2C. This is expected to accelerate further unless greenhouse gas emissions are cut.
Thank-you. I have always suspected that a percentage of the objections, or at least confusion over AGW among lay people, is due to semantics. I believe that there is a need to put more emphasis on climate disruption as a consequence of human activity, rather than dwell on warming.
I understand the general concept of destabilizing a system by pushing more energy than it can handle into it, and I suspect most people do as well. Unfortunately the term ‘warming’ has no such connotation and instead sounds somewhat benign. Perhaps it would be better to use terms that invoke more negative images when referring to this idea in public.
Podargus,
One thing you may have noticed about water the world over is that it seeks and finds equilibrium in a short space of time and with all the various ocean influences that have occurred over a half century that have caused various SL rises and falls not one has caused an increase above 1963 king tide levels at that benchmark except floods and cyclonic surge.
Maybe you have some evidence of your own that says otherwise but the local marine scientists don’t disagree.
Podargus
“Sea levels differ across the globe for various reasons.What the science is telling us is that the overall level has been and is rising and at an increasing rate.At the moment this is mainly due to thermal expansion due to higher temperatures.”
What “science” is telling us is that a satellite in circular orbit around a pear-shaped geoid with flat spots can measure something that is not only not parralel but is rising and falling from so many influences by the second, minute, hour ,day etc. and gives you that answer in mm per year.
That would need a lot of assumptions in that computer program.
Also, according to the Argo floats the ocean is not warming.
What about auto correlation?
DV8,
“Perhaps it would be better to use terms that invoke more negative images when referring to this idea in public.”
What if the hypothesis of ACO2e GW is wrong?
DV8, you said:
“Would it be fair to say AGW is driving the world towards more active weather, rather than in the direction of overall warmer weather?”
The answer is NO!
One of the effects of “Global Warming” is that for every degree that the temperature rises in the tropics there is a corresponding increase of 3-5 degrees at the poles. Thus GW reduces the temperature gradient vs latitude and that has the result of reducing the severity of extreme weather events.
If you don’t believe this, I recommend that you look into what history tells us about extreme weather during the recent “Little Ice Age”.
I have been following this discussion for almost a year now and I am not sure where or how to begin. Perhaps the beginning. That is to say that I do not aprciate tepests in a teapot. Argyments over 2 year starting points are meaningless and prove nothing, The topic as I understand it is the EARTH and it’s waming, climate change, etc. Considering the size of the object should’nt we consider a longer period than a decade or two?
If the period is taken as a thousand or million years, then data from artic ice samples shine differant light on the topic. It is clear that over very long periods the Earth has been cycling between Ice Ages and higher temperatures. From the data it is clear that at the present time we ar not close to either peak. Discussions based on small periods lead to a lot of cleaver math that can be based on GIGO.
I certainly agree that we are in a period of temperature rise. I believe it to be premature to place the current rise, which I consider normal, on an element which is necessary to the welfare of life. There can NOT be sustainability carbon the food of plant life. Ther is NO proof of the suspect being a cause or contrbuter to the current Temp. rise.
I do strongly agree that the best and most satisfactory way of maintaining a clean air environment is withnuclear power. But we should not destroy that which man has created and benifited from unless we KNOW it is destoying us.
Len,
Others can respond much better than I, but I would keep in mind that the connection between rising levels of CO2, due to combustion of fossil fuels, and a global increase in temperature is not based on some fuzzy ‘statistics’ or probability. There is a physical mechanism, which is fairly well understood.
Barry, glad to see some renewed focus on the misinformation and misunderstandings about climate change at this site; it had begun to look almost entirely about promoting nuclear and attacking renewables.
The will to carrying through with an adequate response ultimately depends on public acceptance that there is a genuine need – and that is still seriously lagging. With wide acceptance that action is essential the choices – nuclear, renewables, CCS with their respective pro’s and con’s, will be approached much more pragmatically rather than continue to be used as a wedge to divide and dissipate efforts towards genuine emissions reductions.
Until the majority in the middle demand it we’ll see the focus remain on the debate between acceptance of the problem or denial and between the green-left (100% renewables) and conservative right (what problem?) and not on solid policy to produce the needed solutions.
The campaign to undermine public confidence in climate science is widespread, well funded and supported by powerful interests and public figures. You won’t get a productive debate over nuclear and renewables as long as middle Australia is being misinformed about the importance and urgency of the issue.
Ken,
“The campaign to undermine public confidence in climate science is widespread, well funded and supported by powerful interests and public figures. You won’t get a productive debate over nuclear and renewables as long as middle Australia is being misinformed about the importance and urgency of the issue.”
How about the importance of scientific truth?
Like the warming for the last 13 decades averaging around 0.06 per decade [ for many of which ACO2e was not a consideration] just as it has since satellites took over.
http://www.drroyspencer.com/2011/01/dec-2010-uah-global-temperature-update-0-18-deg-c/
Barry
Good post again. Have you seen the latest post on the Global Warming Superheroes website:
http://globalwarmingsuperheroes.com/global-warming-denial/help-us-find-the-leader-of-the-global-warming-hoax/
Jeff
“Scientific truth”, Drongo? You seem to have the appropriate quotations from the deniers bible all ready to hand.This is just like the fundamentalists in various religions.Selective quotes from fantasy land combined with a peculiar personal spin.
If you choose to place yourself beyond rational thinking then that is your problem.I am sure that there are many venues where your views are welcomed.Your proselytizing here is irrelevant and boring.
The bizarre thing about the “skepticism” one gets from the Drongo crowd is that its whatever comes in hand at the time.
Here, the drongo pitches the vale of “scientific truth” but of course his fellow travellers spend much of their time descrying scientific truth as a species of faith on the basis that “skepticism is at the heart of science”.
Both claims are of course excursions into semantic misdirection. Scientists are leery of truth claims at the best of times and “skepticism” is not what those who have misappropriated the mantle in order to allow them to recklessly and mindlessly jeer from the sidelines say it is.
Science is not the project of any one scientist but the result of a sustained scientific endeavour connecting past present and future humanity. Accordingly, scientific rigour in methodological design and reporting is the sine qua non of science. This allows scope both to corroborate findings and interrogate inferences. Scepticism is possible precisely because what has been revealed is done so through usages established by consensus. Because these practices are explicit, they too can be interrogated and where a case is made out for better practice, supplant an older set of consensus with a new and more illuminating set of conventions — i.e a new consensus.
What is typically proposed (though I doubt they even understand the episteme they blurt out here) as “at the heart of science” is not skepticism (a rational and coherent critique seeking intellectually parsimony) but a form of intellectual nihilism based on nothing more than the general claim that absolute truth is unattainable.
If it is really their assertion that we make nothing at all of what we take to be observable reality then their objection too would be moot. The loudmouthed “skeptics” can have nothing worth listening to. Those of us who continue to accept that the universe is ,in principle, knowable will continue to use this knowledge to inform public policy and the “skeptics” (or on some other day), those appealing for “scientific truth” can please themselves, or not.
[…] No (statistical) warming since 1995? Wrong […]
Scientific truth! Oh dear, didn’t realize it was such a touchy subject.
Would you settle for “a few facts” then?
And then maybe you both could address them instead of ad homming sceptics.
Maybe “scientific truth” is only a problem for those of the CAGW persuasion?
http://www.creatingtechnology.org/truth.htm
Spangled continued as follows:
Disingenuous. It’s out of the denier top ten trolls. You didn’t deploy it de nouveau
You’re the one with the allergy to facts. They give you gas.
Again, you use a term that you don’t understand. You think ad hominem is a synonym for derogating someone by lampooning their claims. It isn’t. Ad hominem arguments are those that challenge the value of propositions on the basis of the attributes of the proposer. Thus, if I were to say that because Al Gore is fat or has a large carbon footprint, his arguments on mitigation ought to be discounted, that would be ad hominem. I’m sure I’ve heard someone put that case.
For the record, I never derogate sceptics for being sceptical. Scepticism [BrE], as I said above, is a rational and coherent critique seeking intellectual parsimony. I do derogate those who make incoherent claims in areas likely to subvert good public policy.
Fran,
Please stop telling me how wonderful you are and show me by dealing with the facts.
I know Poddy finds them religious and boring but I’m sure you don’t.
Also for anyone wondering about current SSTs, they are even cooler than land:
http://www.drroyspencer.com/wp-content/uploads/AMSRE_SST_thru_Dec_10.gif
Podargus,
We could apply the Tom Keen “trick” of reversing a few words in your comment (of 4 January 2011 at 8:20 AM) and it would be equally as valid as your statement. For example:
SD – I think you are mistaken, misguided and that the course you advocate – inaction on emissions – is dangerously irresponsible.
It seems clear that whoever composed that particular question knew that ‘statistically-significant ‘ is a technical term requiring a technically correct answer, knew that the period was too short to allow an unequivocal ‘no’, knew that the general public would equate ‘no statistically significant global warming’ with no real warming. And knew that Phil Jones would answer it honestly. Turning that honesty against him by deliberately misinterpreting what was said is contemptible. Deliberately repeating that dishonest interpretation of that answer as some kind of ‘evidence’ that Phil Jones thinks the planet isn’t warming is equally contemptible. If Spangled Drongo wishes to consider this an ad hom comment about him, he is entirely welcome.
Ken Fabos,
“Turning that honesty against him by deliberately misinterpreting what was said is contemptible”
As well as your ad hom your cognitive dissonance is also showing.
I quoted what he was asked and what he replied. You make more assumptions than GCMs.
There is good cause to be sceptical of ACO2 caused warming as per those other [and more important] facts I have since listed, but that does not in any way invalidate the need for NP.
Following on from those SSTs, NASA GISS doesn’t include them in their calibrations but instead extrapolates from some dubious land temps however if they did, their figure would be nearer to zero, instead of which it will be much higher.
Seeing how the barking dogs here don’t wish to discuss facts it’s probably better if I depart.
Len Rubenstein,
As you point out, one needs to look at climate change over a longer timescale than a decade or two. Ice cores provide an excellent record of past temperature in Antarctica (~700,000 years), Greenland (>50,000 years) and some other locations.
You can access some of the Greenland data at:
http://ftp.ncdc.noaa.gov/pub/data/paleo/icecore/greenland/summit/gisp2/isotopes/gisp2_temp_accum_alley2000.txt
The data covers 49,000 years counting backwards from 1905.
If you look at the data you will find that for most of the last 9,000 years it has been hotter than even the “Warmest years on record” that Hansen at NASA/GISS keeps telling us about.
If you don’t have time to plot the data for yourself, here is a link that shows it:
http://www.ncdc.noaa.gov/paleo/pubs/alley2000/alley2000.html
Most of the folks on this site seem to believe that the rapid warming since 1850 has been caused by Carbon Dioxide even though that hypothesis fails at all timescales.
For example, the Vostok (Antarctic) ice cores clearly show that CO2 concentrations correlate closely with temperature though several glaciation cycles. However, as the CO2 concentration lags temperature rise by ~800 years it is nonsense to claim CO2 causes global warming!
Burt Rutan has been a very creative engineer, so he is all too well aware that engineers have to get things right or buildings collapse, planes crash and ships sink often with great loss of life. Climate scientists on the other hand can make all kinds of absurd statements and be proved wrong time after time without losing their reputation or their livelihood.
You can download Burt Rutan’s views on climate change from this website:
http://rps3.com/Pages/Burt_Rutan_on_Climate_Change.htm
This blog advocates a rapid build up in nuclear power generating capacity While I am a strong supporter of that idea my reasons have nothing to do with “Catastrophic Anthropogenic Global Warming”.
I’m impressed by the way
1) sea level rise which is measured in millimetres can be assessed by the look of a beach front
2) temperature rise which is measured in tenths of a degree can be measured millennia before thermometers were invented.
Camel – a bit of homework for you – write a hundred (make that, in your case 1000) line
“CO2 can be a driver or a feedback mechanism”
Read this
http://www.realclimate.org/index.php/archives/2004/12/co2-in-ice-cores/
– it is nice and simple for you to understand. Although, I suspect you already understand!
Drongo – thankyou for the link to Dr Roy Spencer’s work.
Although why anyone would take any notice of his “research” puzzles me.
Here is his “biography” – makes interesting reading;)
http://www.desmogblog.com/roy-spencer
Well,drongo,dear boy,I know not what ails thee.Not particularly interested in finding out,either.
As your version of the “facts” and “scientific truth” doesn’t appear to measure up to the rational standards of this site it is probably better that you do depart as you suggest.You have managed to hijack this thread and turn it into a farce.That was probably the intention.
From my personal perspective I think your chief complaint is that you are a common,garden variety troll for whatever reason.
The best treatment for trolls is starvation and that is what I propose to apply.
Good idea Podargus – I agree.
Peter Lang,I really haven’t seen too many climate change alarmists on this site.Seems like the discussions are fairly rational,at least until the likes of Camel,drongo or,heaven forbid,the good Doctor Addinall get involved
Then again,I suppose beauty (or rationality or alarm) is in the eye of the beholder.
[…] […]
Ms. Perps,
As you surmise, I am well aware of Jeff Severinghaus and his tortured logic. From my perspective, like James Hansen, he is a perfect example of a scientist who can make stupid statements without any fear of losing his job or the respect of his peers.
With regard to Roy Spencer, I don’t always buy his arguments but I like the company he keeps (Lindzen, Michaels, Singer, Choi, Baliunas et al.).
While I would be happy to continue this discussion if we can stick to facts and deductions, once the “ad hominem” starts (starve the trolls!) my motivation vanishes.
I plan to return when the subject is something we can discuss without resorting to name calling.
What? The trend over the entire UAH series is about .14 K/dec. RSS gives a little over .16 K/dec.
In fact, the first data point is from roughly 0.95 thousand years before ‘present’, where GISP2 defines ‘present’ as 1950. So the data counts backwards from 1855, not 1905.
In fact, what you will find is that for most of the last 9,000 years it has been hotter than…well, 1855. Which isn’t particularly interesting, especially since the GISP2 location has warmed by about 2 degrees since then, putting current temperatures well above most of the past 9,000 years.
Of course, this is the temperature at a single location. What we’re really interested in is the global mean temperature, for which you require proxy reconstructions with good spatial coverage.
And now for something completely different:
http://www.chinadaily.com.cn/china/2011-01/04/content_11788510.htm
Uncle pete, these Chinese ‘nuclear technology breakthrough’ articles are starting to irritate me. They’re all so poorly written that only people who already have considerable basic knowlefge of nuclear tech can begin to interpret them. The technology in question is supposedly reprocessing, but reprocessing won’t give a sixty-fold increase in fuel utility. Only breeder tech will do that. They haven’t exactly made themselves clear in what they’re talking about.
A commenter on Atomic Insights suggested that the new reprocessing tech might remove some neutron poisons from spent fuel, making it a better fit fot breeder reactors. Perhaps this is what is meant.
Steve K wrote at 0236, 4Jan11:
I beg to differ. There is considerable dissent within the Climate Science community over the physics. All are agreed that doubled CO2 without feedbacks would raise the temperature by around 1 DegC. The big argument, far from settled, is over the magnitude and sign of the feedbacks.
The majority are “Positive Feedbackers” and predict (“project”? “Guess”?) a final result between 1.5 and 6 DegC. Otgher climate scientists are “Negative Feedbackers” and predict (“project”? “Guess”?) a final result between 0 and 1 DegC.
This great range of views is caused by the great unmeasurables:
a. What will be the effect on Relative Humidity of an increase in temperature?
b. What will be the required change in evaporation rate required to support that?
c. What sort of clouds will result, and,
d. What effects will these have.
Anyone who thinks that this science is settled is smoking something very strong.
Fred, on 5 January 2011 at 10:07 AM — One can eawsily provide a good estimate of the transient response to the excess CO2. Here is an extremely simple model to calculate that estimate:
http://www.realclimate.org/index.php/archives/2010/10/unforced-variations-3-2/comment-page-5/#comment-189329‘
Those few who claim an equilibrium climate sensitivity lass than the transient response clearly fail to understand the applicable physics. [Two I know about who have published such incorrect estimates are meteorologists by training who have wandered into something they clearly misunderstand.]
Fred,
There are always disagreements in science, but that is very different from “dissent” carefully crafted for political reasons. The overwhelming view is that feedbacks are positive and of sufficient magnitude to result in a climate sensitivity of about 3C. SkepticalScience summarizes the recent work on feedback from the (somewhat) contentious issue of changes to cloud behavior here:
http://www.skepticalscience.com/a-cloudy-outlook-for-low-climate-sensitivity.html
http://www.skepticalscience.com/an-even-cloudier-outlook-for-low-climate-sensitivity.html
Andrew Dessler very clearly deals with feedbacks entirely without reference to climate models here:
Fred,
You are wrong to imply that changes to atmospheric humidity and cloud behavior are unmeasurable. There is observational data for both. See Dessler’s work on clouds for example.
Bravo on the renewal of the influence of carbon plus and minus. But can we agree on some facts without oneupmanship? Would you agree that ifone examines temp rise over the last 150 years and look at the slope of the rise. After looking at the slope examine the rate of CO2. As the CO2 increases there apears to be almost no affect on the temp slope. It seems to me to be a bit hasty to take a potshot at a target which unlike other (greenhouse ) gases appears to be benificial for plant life which is important for the wellfare of man. Certainly based on the phisical data the curves give us it would appear difficult to select a cause other thann that of a normal earth cycle. as described above by others the ice samples reveal nothing that hasn’t occurred already. -Len
Len Rubenstein, on 5 January 2011 at 1:18 PM — Its clear you didn’t attempt to understand my simple model linked above nor attempt the arguments, all non-model, over on Skeptical Science.
But maybe instead you’ll take the time to watch/listen to Dr. Richard Alley on Earth’s Biggest Climate Control Knob
http://blogs.nasa.gov/cm/blog/whatonearth/posts/post_1262067702260.html
Fred said:
“There is considerable dissent within the Climate Science community over the physics.”
Could you provide somes links to some peer-reviewed papers which are a point of debate about the physics?
Among many others, quokka kindly responded to my post on scientific non-settlement thus:
I am not disputing that one can attempt measurement of these, just that the results are inconclusively woolly. There is measurement support for example for an increase in the evaporation rate of 5%/DegC. The theoretical maximum, providing relative humidity is kept constant (a very brave assumption) is about 7%/DegC. The modellers use a figure around 2%/DegC, presumably based on their peer-reviewed measurements, and a constant RH, meaning that they get a 7%/DegC increase in atmospheric water vapour without paying for it with the same increase in evaporation rate. (If they used 7%, they would not be able to achieve energy balance at the surface). A review of the literature reveals no widespread agreement on this key parameter. The same is true of clouds.
It is my concern that this area of uncertainty, which leads to the enormous spread of predictions/projections/guesses about the temperature effect of a doubling of CO2 is not being widely discussed, and is not generally placed as a genuine uncertainty before policy makers.
It seems to be a theme on this thread, and other threads on BNC, of using the phrase “catastrophic AGW”. This term is being used mostly by dissenters of main-stream climate science – in an antagonistic way as far as I can tell. As for what “catastrophic” means, it is entirely the viewpoint of the individual interpreting it.
Current models projecting biological responses to climate change suggest that up to 60% of species could go extinct if the warming trend continues unabated. We are already experiencing in the current mass extinction event (the Holocene extinction) a rate of extinction several hundred times higher than the background rate, due primarily to human activities.
Given that earth is all we Homo saps have as a habitat, and that we rely on functional ecosystems to provide us with food, good health and the backbone of the economy, I fail to see what wouldn’t be “catastrophic” about such extreme potential extinction rates, on top of what we are already experiencing.
So a question arises from this: if the current climate models were assumed to be reasonably accurate, would those dissenters using the “catastrophic AGW” phrase find this alarming?
Tom Keen asked:
“Could you provide somes links to some peer-reviewed papers which are a point of debate about the physics?”
I would like to thank Tom for his question.
I was going to link to some papers, particularly Spencer’s recent paper on clouds, but instead came across this email-debate between Spencer and Dessler, http://www.drroyspencer.com/2010/12/dessler-and-spencer-debate-cloud-feedback/ which i think encapsulates the differing views within the Climate Science community.
MartinM,
Thanks for attacking my “facts” rather than calling me names.
The data set I linked to was filed in the year 2000 and the first data point was at 0.0951409 ka “Before Present” which means 1905 rather than your suggested 1855.
Like you I was troubled by the fact that this excellent data set stops before the modern warming. Consequently, I visited the NCDC in Asheville, North Carolina last October to find out what could be done to bridge the gap between 1905 and the present day.
The scientists at NOAA were very helpful and pointed me to what I believe is the best instrumental data available (Danish Meteorological Institute).
My two part post on this can be found at “Digging in the Clay” under the title “Dorothy behind the curtain”.
Those posts address some of the other points you raise. For example, my analysis does not claim to be “Global” as the data relates to high latitudes in Greenland.
If you don’t like my analysis, something very similar was posted independently on WUWT by Don Easterbrook a couple of days earlier:
http://wattsupwiththat.com/2010/12/28/2010%E2%80%94where-does-it-fit-in-the-warmest-year-list/
Barry – it’s not clear to me, but I think you’re using OLS regression here?
I think you should be using an autoregressive model of some kind – say an AR(1) + trend or an ARMA(1,1) + trend model. The sequences are clearly autocorrelated and you’ll get spurious significance by using a simple error + trend model.
Yes, it is the MLE equivalent of OLS. There may be some autocorrelation – that is one of the assumptions I alluded to above. However, this is generally more expected when looking at monthly rather than yearly anomalies.
Same old elementary error of analysis here.
If there is a stochastic trend in the data (there is) you will imput a narrow range of potential trends from your model.
In other words, making the model more consistent with the observable data (including an autoregressive process), you get back to the concusion that there is nothing exceptional about the data beyond stochastic variation since 1995 (no discernable trend)
That is the part you got completely wrong.
The bit you got right was the conclusion that you need a longer track record – and an especially longer track record when the data are clearly non-stationary (or exhibit a stochastic trend).
The message is to dial back on the confident claims about how the temperature proves this or that.
gallopingcamel:
No, it’s nonsense to claim that the delay proves that CO2 can’t cause global warming! The delay simply means that it takes time for the whole oceans to warm and for the CO2 to come out of the oceans.
By the way, I’ll stop putting in the boring exclamation marks if you stop. Deal?
That’s just unsubstantiated hand waving, Geckko. It is also confusing, as you say that there both is a trend and there isn’t one. Which is it?
If you believe that the statistical model results are spurious, then you can demonstrate it with some synthetic data that has the (null) properties that you suggest. It’s simple enough to simulate this process. You are essentially saying (at one point, anyway) that the data show only noise about a mean. Yet this ‘no trend’ model is poorly supported compared to the alternative, as I showed with the evidence ratio. If you think this is wrong due to violation of assumptions, then please show otherwise, quantitatively. Also demonstrate your assertion that the data show temporal autocorrelation and that this affects the conclusion of the analysis.
Otherwise, your critique is at best unsupported and at worst meaningless.
That’s a perfectly reasonable assumption – indeed, it’s the one I first made when I looked into this about a year ago – but it’s incorrect. Take a look at the oxygen isotope data from which the temperature reconstruction is derived. It was filed in 1997, but the first few ‘years before present’ values are negative, and the notes clearly identify 0BP as ‘AD 1950 SUMMER to AD 1949 SUMMER’.
I took a look, and it seems to me that your results using the DMI data are basically similar to those found by Alley in the paper I linked; a little over 2 K warming since the end of the ice core temperature record.
What I don’t understand is how, given those results, you can then claim that ‘…for most of the last 9,000 years it has been hotter than even the “Warmest years on record” that Hansen at NASA/GISS keeps telling us about.’ In fact, your own graph shows that current temperatures are greater than any seen in the last 3,000 years. If you extend that plot to cover the last 9,000 years, you’ll find only a few short peaks where past temperatures have exceeded present ones. The bulk of the past data lies well below present values.
Easterbrook’s analysis fails to do what you and I both did independently; account for the past century or so of warming. His figures 3, 4 and 5 all end at the end of the GISP2 record, which is the only reason he can claim that “…virtually all of the past 10,000 years has been warmer than the present.”
Good luck establishing that.
“That’s just unsubstantiated hand waving, Geckko. It is also confusing, as you say that there both is a trend and there isn’t one. Which is it?”
I think he meant a stochastic trend, which means a spurious one.
The question of whether there is any autocorrelation is easily settled with a plot of the autocorrelation function (acf() in R). You may want to detrend it first. You can also test the fit of various ARIMA models by using the arima(data,order=c(a,d,m)) function.
Ideally, a number of tests besides the AIC should be used to pick a model. Durbin-Watson results would be interesting, for example. But it’s not really valid to pick the null hypothesis model on the basis of the data to be analysed – it results in circular reasoning. You need separate out-of-sample data to do model selection and significance testing separately, which we don’t really have enough of.
I noticed that Barry used the two temperature series which use land based data sources, rather than the two satellite data sets. Is there a good reason for this?
I also note that the GISS data set shows more recent warming than the other three data sets. Is there a good reason for not excluding this set from analysis?
Finally, is there any estimate of the uncertainty in each data point in the sets under consideration? (From the variation between the 4 data sets there must be considerable uncertainty.) Drawing trend lines through noiseless data is one thing, but I think the uncertainty in the line must increase if the data is uncertain.
MartinM,
Many thanks for your comments. With regard to the start date for the GISP2 data, you are right. It is 50 years earlier than I assumed, so I need to make some changes to my plots.
As you point out, the temperatures reached in the mid thirties and late nineties (at least in Greenland) have been exceeded over less than 10% of the last 9,000 years.
It seems that we agree on slightly more than 2K of warming since 1850. What was the source of your data?
Fred, on 6 January 2011 at 7:22 AM — There are four major global surface temperatrure products. Of these, only GISS attempts to treat the Artic properly; the others in effect ignore it. However, all four are in substantial agreement.
As for the sat4ellities, those attempt to represent “the lower troposphere”. Most of us don’t live in a hot air ballon.
I cannot understand why statisticians insist on fitting a regression line to data that is quite clearly periodic.
The underlying mathematical model in this argument strikes me as incorrect.
RCS, on 6 January 2011 at 9:32 AM — There is an annual periodicity, which is not of interest. It could largely be removed by any low pass filter such as using annual averages.
“All models are wrong. Some are useful”
— statistician George Box
if you believe giss and hardcru numbers and base your statistics on them – madoff has some stock advice for you. His numbers show you will get a fabulous return.
A spectacularly inane comment in light of the fact that ALL temperature records show nearly identical warming:
http://upload.wikimedia.org/wikipedia/commons/7/7e/Satellite_Temperatures.png
galloping camel:
Where is your proof that if A changes B then C cannot change B?
(BTW, for those unfamiliar with the issue, A = orbital variations, B = temperature changes, C = CO2 change)
Chris O’Neill,
Do you believe that orbital variations are a major factor driving global temperatures?
If so, do you believe that CO2 only has a minor effect on the global thermostat?
galloping camel:
They have been, but very little in the last 100 years and none in the last 50.
It produced about 2K of the temperature change from 100ppm of change in the past. Of course, we’re on our way to producing much more than 100ppm increase in CO2.
I’ve answered your questions. When are you going to answer mine:
Where is your proof that if A changes B then C cannot change B?
Chris O’Neill,
All of my remarks on this thread apply to “B” (temperature changes) and “C” (CO2 change). You are the one who introduced “A”.
Nevertheless, in a sporting spirit here is my view of things. Milankovitch cycles affect global temperatures over periods of 10,000 years or more. Hence it is plausible to suggest that “A” (orbital variations) are the primary driver of the oscillations seen in the Vostok ice cores.
At that timescale, it looks as if “A” is driving “B”. (Temperature changes) while “B” drives “C” (CO2 changes) with a lag of 600 to 1,000 years .
While this is just a hypothesis, it has the virtue of simplicity . Have you got a better hypothesis?.
Chris O’Neill, you said:
“It produced about 2K of the temperature change from 100ppm of change in the past. Of course, we’re on our way to producing much more than 100ppm increase in CO2.”
We can agree about the ~2K increase in temperature in Greenland since 1850 but the hypothesis that it was caused by the 100 ppm increase in CO2 concentrations does not fit the facts. Here is a plot of temperatures over the period in question:
http://diggingintheclay.files.wordpress.com/2010/12/coastal-average.png
As you will see, there was a rapid rise in temperature that ended in 1934. After that there was a steep decline ending in 1994. After that temperatures resumed rising as asserted by Barry Brook at the top of this thread.
There must be other factors at work that overwhelm the contribution of CO2 given the 60 year decline during a period when CO2 concentrations were increasing.
galloping camel:
I was not referring to this temperature increase but to the global temperature increase coming out of ice-ages which totalled about 5-6K. 2K out of this total was caused by CO2. Consequently, your statement:
is not relevant to this.
galloping camel:
So you’re suggesting that “A” does not exist. i.e. that B happens by itself with no cause. This is the problem with the contrarian position. They say there is climate change but they avoid the fact that climate change always needs a cause.
This, of course, says nothing about what fraction of the oscillations are directly due to the “primary” driver and what fraction are due to the various feedbacks in that situation including albedo and CO2.
As indeed I pointed out above.
So you think simplest is always best? There is nothing in what you’ve said that means that those CO2 changes cannot then go and cause temperature changes themselves. You’re just asserting that they can’t.
Chris O’Neill,
I think we are edging towards agreement. Certainly I have never said that CO2 changes can’t cause temperature changes.
Also I have never suggested that “A” does not exist. To the contrary it appears to be a more powerful driver of global temperatures than “C” (CO2 change) at least on Vostok timescales.
No, I don’t always think that “simplest is best” but one should avoid complexity if simple will get the job done (Occam’s Razor).
gallopingcamel:
Then what does this mean:
Is it supposed to mean it’s proof that CO2 can’t cause warming? Severinghaus never said it was proof that CO2 causes warming. So what were you trying to say?
I was trying to work out the point of saying, “You are the one who introduced “A”.”
was
Not necessarily. There was a huge feedback from ice albedo. I’m not an expert but I believe the ice albedo feedback associated with glaciation doubled the temperature change from other drivers. So the 2K from CO2 and its immediate feebacks could have been doubled to 4K out of the total 5-6K. So starting from an initial 1K caused by astronomical forcing, the various feedbacks such as short term water vapor, medium term ice albedo, and long term CO2 could well have multiplied that by a factor of 5 or 6. Such a high feedback factor is obvious from how much the earth’s temperature has varied over the past 3 million years from relatively small astronomical forcing.
The big IF. It doesn’t get the job done because astronomical forcing and ice albedo feedback on their own are not enough to do the job.
Using Occam’s Razor in this context reminds me of the contrarian view that most of the current warming is not caused by CO2, contrary to expectations, AND that most of the current warming is caused by something else AND that the something else is unknown. If that doesn’t fail Occam’s Razor, I don’t know what does.
@spangled drongo
Wrong.
You should read and understand this account of how problems with the calculation of ocean heat content have been dealt with. It is a fascinating scientific detective story with conflicting lines of evidence with for example the measured sea level rise simply being incompatible with the lack of thermal expansion from a cooling ocean.
It is analogous to the former discrepancies between the UAH satellite temperature record and the surface temperature records being resolved in the favour of the latter. In both cases, the reported discrepancies have been due to issues of instrumentation and calibration. The mainstream of climate science and interestingly climate models have proved correct.
There is a lesson here for deniers who almost wet themselves with excitement when a paper is published that ostensibly provides evidence against AGW. With incredible speed it is echoed all over the blogosphere and represented as THE TRUTH. Real science takes a more measured and cautious approach balancing multiple lines of evidence and reexamining evidence to resolve discrepancies.
Earth system sensitivity inferred from Pliocene modelling and data
Daniel J. Lunt, Alan M. Haywood, Gavin A. Schmidt, Ulrich Salzmann, Paul J. Valdes & Harry J. Dowsett
Nature Geoscience 3, 60 – 64 (2010)
http://www.nature.com/ngeo/journal/v3/n1/full/ngeo706.html
quokka,
Here is a good discussion of the 5 papers that have been done on the Argo floats since 2003 when the data were more reliable, including the latest.
http://wattsupwiththat.com/2011/01/06/new-paper-on-argo-data-trenberths-ocean-heat-still-missing/
If one is happy to continually use doubtful data and believe GCMs without scepticism, then I think “denier” is quite applicable.
Just as I can be sceptical of this:
http://www.nipccreport.org/articles/2011/jan/6jan2011a5.html
If you look at the last ten years temps, there has been no significant change. Now I know that this is a very small time frame and that the temp trends over the last 50, 100 and 150 years are all up but there must be a possibility, however small, that the trend is changing. We could be entering a period of little change or even a trend reversal. I understand that this is unlikely but who knows what the next decade will bring. To fit the IPCC report, we will need a delta t of 0.7k or more or some revision will be called for.
Whatever happens, I am quite sure of one thing, taxing Australians on their CO2 emissions will have no measurable effect on the rate of climate change or the global mean temp at 2100.
coming in a little late, but there’s a nice book which
complements Barry’s final link in this post:
The Cult of Statistical Significance
The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives (Economics, Cognition, and Society)
Mathematicians and statisticians use p-values but don’t worship them, in some life sciences, work
which finds p>0.05 is summarily dismissed … quite bizarre.
[…] Watts and other global warming skeptics, and statements made by climate scientists in interviews such as this one: BBC: Do you agree that from 1995 to the present there has been no statistically-significant global […]